
The industry has spent years debating model size, architectures, and inference tricks. But Meta’s latest research makes something very clear: AI success is still determined by four elements: prompt, grounding, training, and fine tuning, and three of them are fundamentally data problems.
Which means the real bottleneck isn’t compute. It’s data quality, data structure, and data digestion.
Meta’s new Autodata framework reframes this bottleneck entirely. Instead of treating data as a static asset that humans must continuously curate, Autodata turns the model itself into an autonomous data scientist, capable of generating, analyzing, and iterating on its own training data.
RAM @ Meta AI | A framework to study AI models in Reasoning, Alignment, and use of Memory (RAM)
This is not “synthetic data 2.0.”
This is a shift in how data pipelines operate.
1. Why Data Quality Still Determines AI Success
Prompting and grounding matter, but they sit on top of the real foundation:
- the training data that shapes the model’s baseline
- the fine‑tuning data that aligns it
- the evaluation data that determines whether it’s improving
Three of the four levers that determine AI performance are data‑centric.
And historically, all three required human data scientists — expensive, slow, and difficult to scale.
2. The Traditional Data Scientist Bottleneck
Data scientists have always played the critical role of:
- curating high‑quality examples
- grounding tasks in real documents
- designing evaluation rubrics
- iterating based on model failures
This work is high‑cost because it requires human judgment, domain knowledge, and careful harness engineering. Even synthetic data pipelines still depended on humans to design prompts, filters, and quality checks.
3. Meta’s Autodata: A Model That Trains Itself With Data It Creates
Autodata changes the loop.
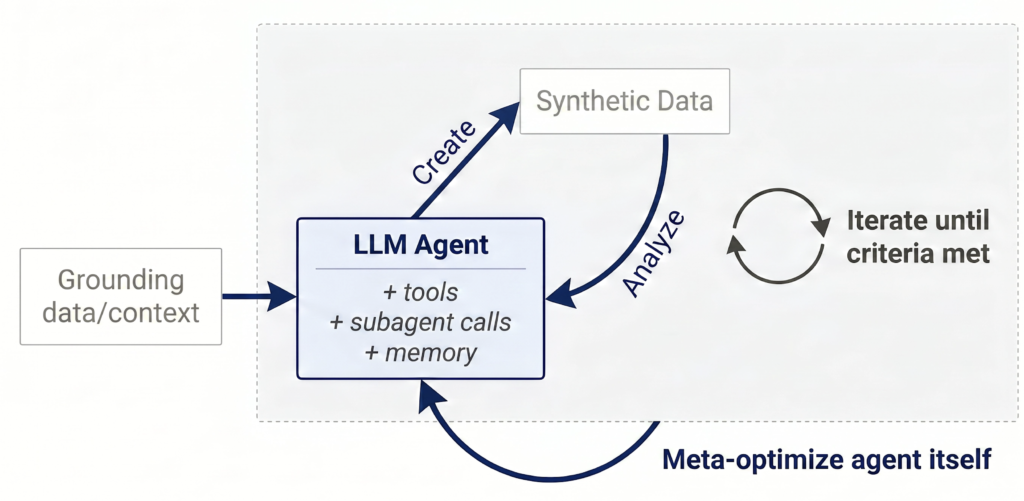
Instead of single‑pass synthetic generation, the model now:
- Data Creation. The agent grounds on the provided documents and uses its existing skills and compute to create training or evaluation data. It can repeat this step after each analysis cycle to incorporate new learnings and improve the data.
- Data Analysis. The agent reviews the data it created to understand correctness, quality, difficulty, and diversity. These learnings feed directly back into the next creation cycle until the data reaches the required standard.
- Data Scientist Loop. The agent cycles between creation and analysis until it is satisfied with the final dataset. Guardrails can be applied to prevent reward hacking, and later generations of agents can build on earlier learnings.
- Meta Optimization. The agent itself can be improved through autoresearch or meta‑harness optimization so it becomes better at performing the data scientist role over time.
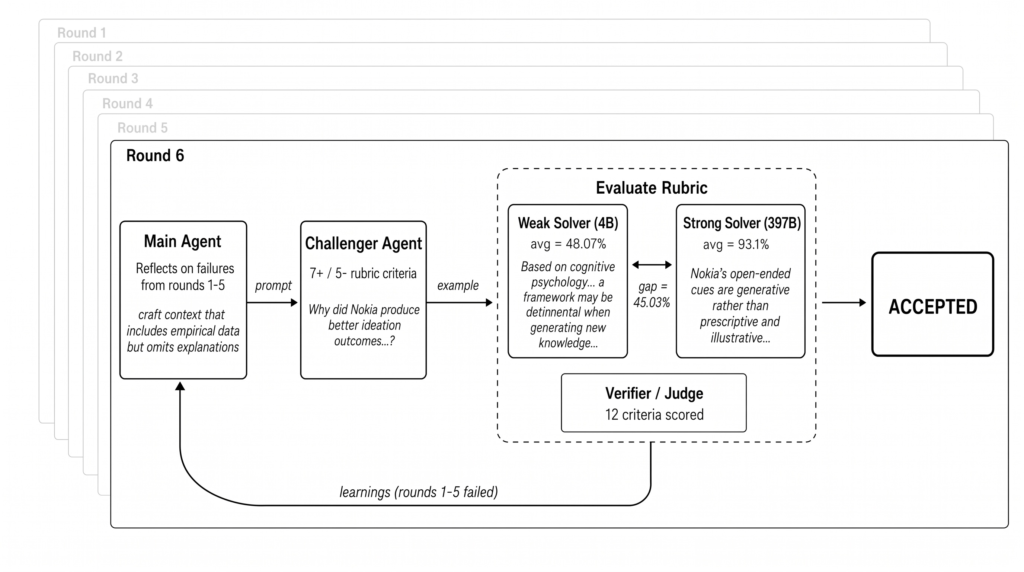
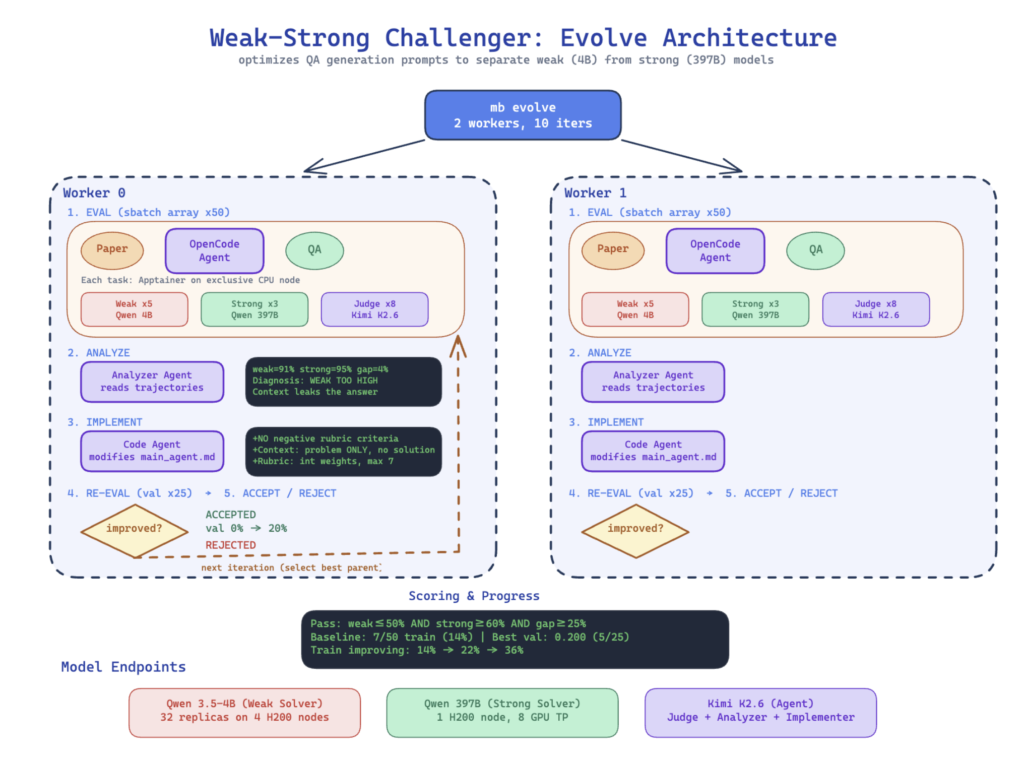
Meta’s implementation uses a multi agent setup with a Challenger, a Weak Solver, a Strong Solver, and a Verifier to ensure the generated data is neither trivial nor impossible. The result is higher quality training data than classical Self Instruct or CoT Self Instruct methods.
This is the first time we’ve seen a closed‑loop, feedback‑driven data creation system that mirrors how human data scientists work.
RAM @ Meta AI | A framework to study AI models in Reasoning, Alignment, and use of Memory (RAM)
4. Reducing the Cost of Human‑Grounded Data
The cost of training data has always come from:
- human annotation
- human‑designed prompts
- human‑designed evaluation rubrics
- human‑driven iteration
Autodata reduces all four.
Meta’s meta‑optimization layer even shows that the agent can improve its own instructions, discovering better harness logic without human intervention.
RAM @ Meta AI | A framework to study AI models in Reasoning, Alignment, and use of Memory (RAM)
This is the part that matters:
The model is not just generating data, it is improving the rules for generating data.
5. AI as the Data Scientist
Meta’s results show that an AI data scientist can:
- enforce paper‑specific insights
- prevent context leakage
- design structured rubrics
- tune difficulty levels
- widen capability gaps between weak and strong solvers
All without manual harness engineering.
This is the beginning of agentic data operations, where the model becomes an active participant in its own training pipeline.
6. A Shift in the Data Operations Pipeline
Autodata changes the relationship between:
- data creation
- data evaluation
- model training
- model alignment
Instead of a linear pipeline, we now have a self‑improving loop where the model continuously refines the data that refines the model.
This transforms data operations from a human‑driven workflow into a compute‑driven optimization problem.
7. Rethinking the Four Elements of AI Success
If prompt, grounding, training, and fine‑tuning determine AI success, and three of them are data‑centric, then Autodata forces us to rethink how these elements interact.
We now have:
- new external grounding (the model grounds itself on documents)
- new internal grounding (the model evaluates its own reasoning)
- new training loops (data improves as compute increases)
- new fine‑tuning strategies (agent‑generated datasets outperform human‑designed ones)
The implication is simple:
Data pipelines are becoming agentic systems, not manual processes.
Where This Leads
Autodata is not just a research milestone.
It signals a future where:
- models generate their own training curriculum
- data scientists supervise strategy, not samples
- data quality scales with compute, not headcount
- grounding becomes dynamic, not static
- fine‑tuning becomes continuous, not episodic
The next wave of AI performance will come from agentic data pipelines, not larger models.
And Meta just opened the door.
Source: Meta Autodata research https://facebookresearch.github.io/RAM/blogs/autodata/
About the Author
Jonathan Wong is an IT and AI consultant with 20+ years of experience leading engineering teams across Vancouver and Hong Kong. He specializes in modernizing legacy platforms, cloud security, and building AI-ready systems for startups and large enterprises while advising leadership on using strategic technology to drive business growth.
Connect with me on LinkedIn